DSGram: Dynamic Weighting Sub-Metrics for Grammatical Error Correction in the Era of Large Language Models
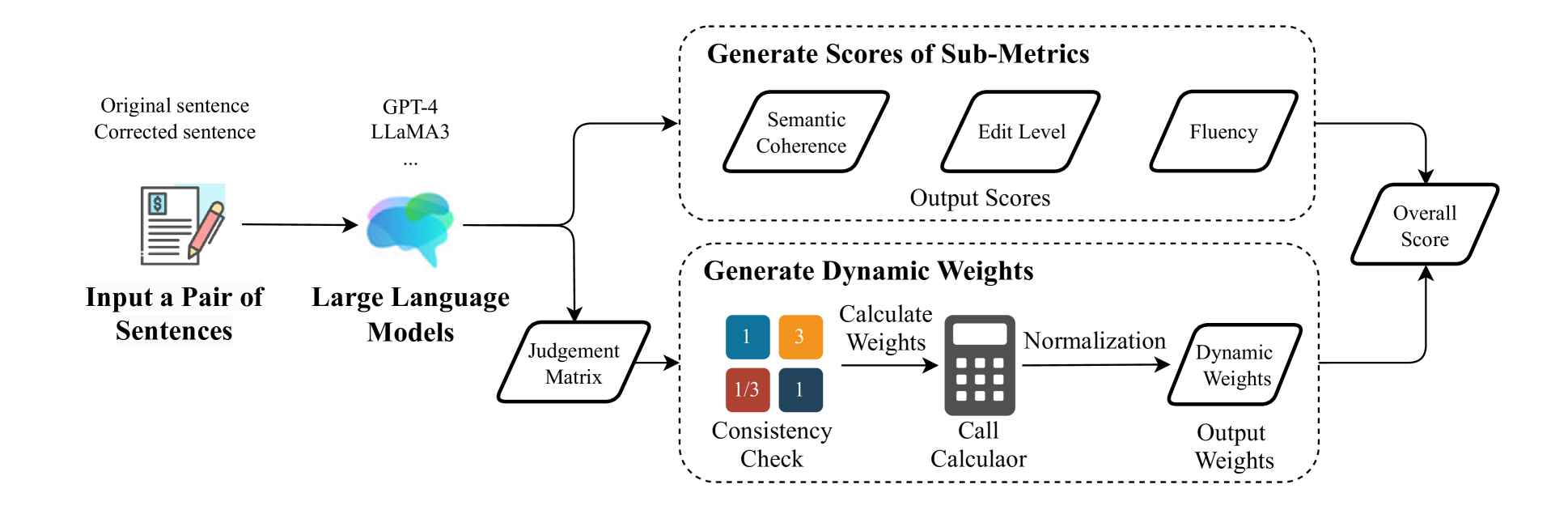
In this study, we propose a novel evaluation framework for GEC models, DSGram, integrating Semantic Coherence, Edit Level, and Fluency, and utilizing a dynamic weighting mechanism. Our framework employs the Analytic Hierarchy Process (AHP) in conjunction with large language models to ascertain the relative importance of various evaluation criteria. Additionally, we develop a dataset incorporating human annotations and LLM-simulated sentences to validate our algorithms and fine-tune more cost-effective models.
Experimental results indicate that our proposed approach enhances the effectiveness of GEC model evaluations.
Motivation
Traditional GEC evaluation metrics have significant limitations when dealing with LLM-based systems. As shown below, BLEU fails to differentiate between over- and under-correction, while SOME cannot capture over-correction. DSGram addresses these gaps with a comprehensive evaluation framework.

Key Contributions
- New Sub-Metrics: We introduce redesigned sub-metrics for GEC evaluation — Semantic Coherence, Edit Level, and Fluency — that address the over-editing problem in LLM-based GEC models.
- Dynamic Weighting with AHP: We propose a novel dynamic weighting method integrating the Analytic Hierarchy Process with LLMs to ascertain the context-dependent importance of evaluation criteria.
- Evaluation Datasets: We present DSGram-Eval (human-annotated) and DSGram-LLMs (GPT-4 simulated), both built on CoNLL-2014 and BEA-2019 test sets for rigorous evaluation.
- Superior Correlation: DSGram achieves higher correlation with human judgments than all conventional reference-based and reference-free metrics on the SEEDA benchmark.
Method
DSGram comprises two main components: score generation and weight generation. By applying context-specific weights to the generated scores, an overall evaluation score is obtained.
Three Sub-Metrics
Semantic Coherence: Degree to which original meaning is preserved. Edit Level: Whether corrections are necessary and appropriate. Fluency: Grammatical correctness and natural flow.
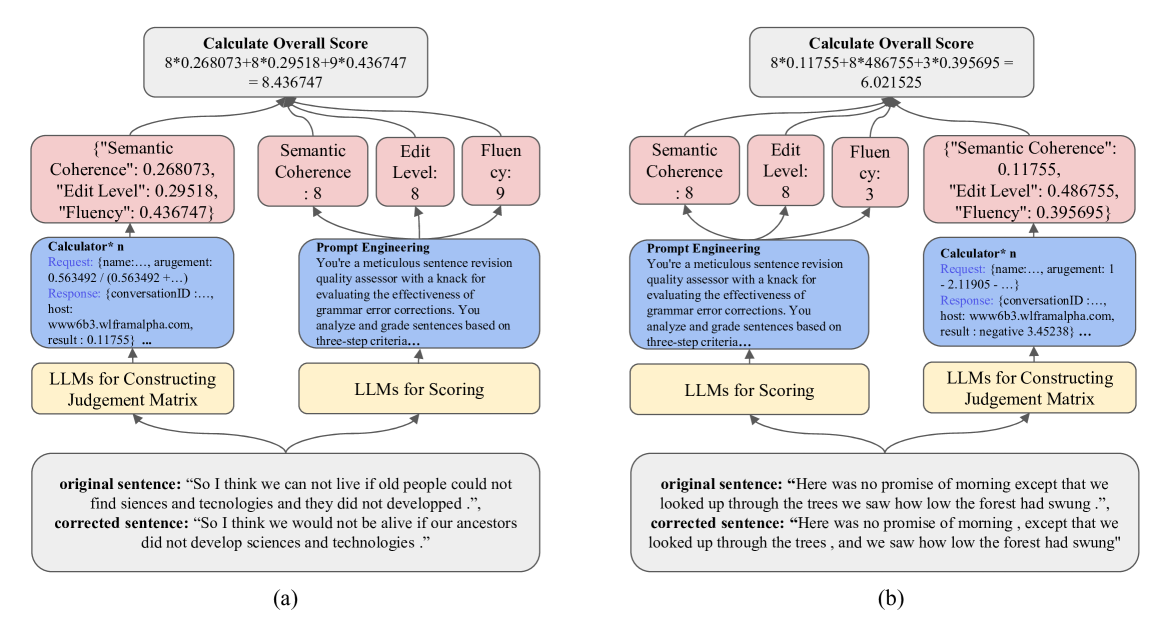
Dynamic Weighting via AHP
Uses LLMs to construct pairwise comparison matrices for each sentence, with consistency checks and eigenvector normalization. Formal texts emphasize Edit Level; casual texts prioritize Fluency.
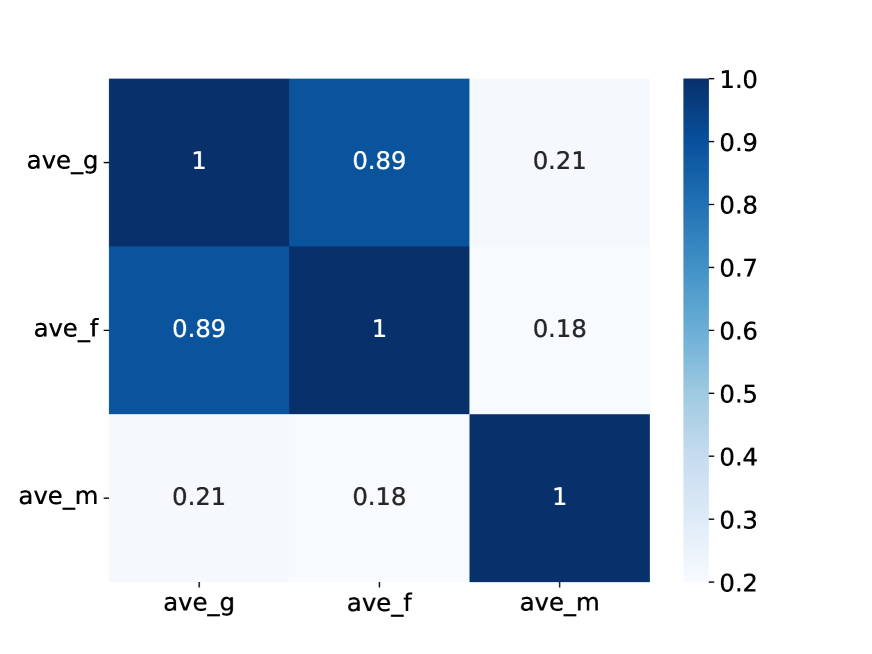
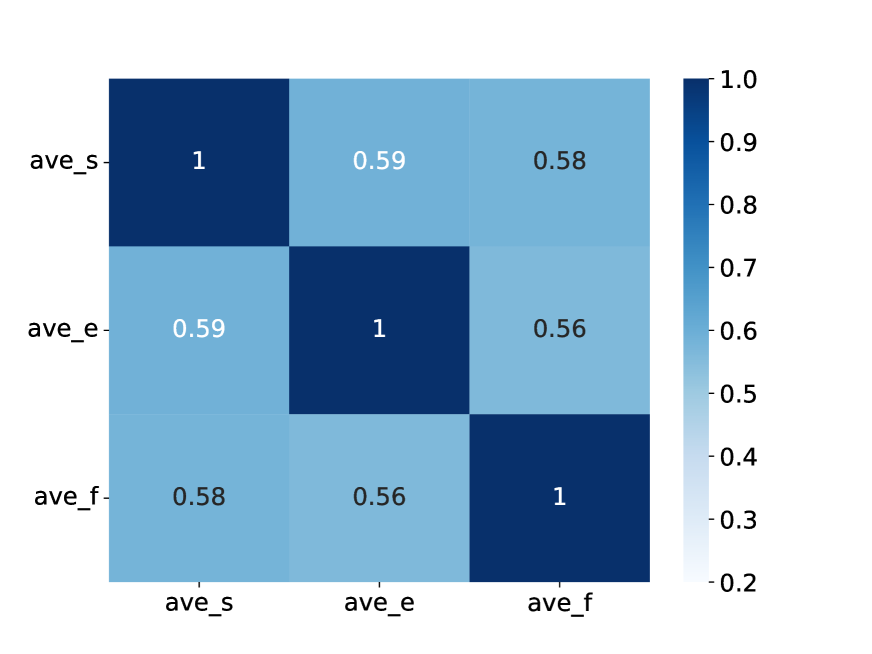
Sub-Metrics Analysis
We redesigned the sub-metrics to reduce redundancy and improve coverage. The original SOME metrics showed high correlation (0.89) between Grammaticality and Fluency. Our new sub-metrics achieve a more balanced distribution.
Results
DSGram's correlation with human feedback surpasses all conventional reference-based metrics (M², ERRANT, BLEU) and reference-free metrics (GLEU, Scribendi Score). Fine-tuned LLaMA3-8B and LLaMA2-13B models on DSGram-LLMs dataset also outperform their few-shot counterparts, demonstrating the framework's practicality with cost-effective models.
Citation
Acknowledgments: This work was done during the author's research internship at Peking University. We thank Prof. Xiaojun Wan and all colleagues from the Wangxuan Institute of Computer Technology for their guidance and support.