
My name is Jinxiang Xie (pronounced “JIN-shee-ahng SHEE-eh”). I am a graduate student at Nanjing University. I earned my Bachelor’s degree in Information and Computing Science from Beijing Jiaotong University. I was a research intern at Microsoft, where I have the privilege of working with Principal Researcher Justin Ding. Prior to this, I gained valuable research experience at Peking University under the guidance of Prof. Xiaojun Wan.
My research focuses on leveraging Large Language Models to address complex problems.
Feel free to reach out if you’d like to discuss research or explore potential collaboration!
AI Researcher
- Research focus on LLMs and NLP
- Internships at top institutions
- Publications at AAAI, ACL
Content Creator
- Technical blogs with 500K+ views
- Active on Xiaohongshu
- Articles about Tech & Humanities
Life Explorer
- Visited 9 countries worldwide
- Traveled to 32 provinces in China
- Rich experience in social work
Publications
Under Review
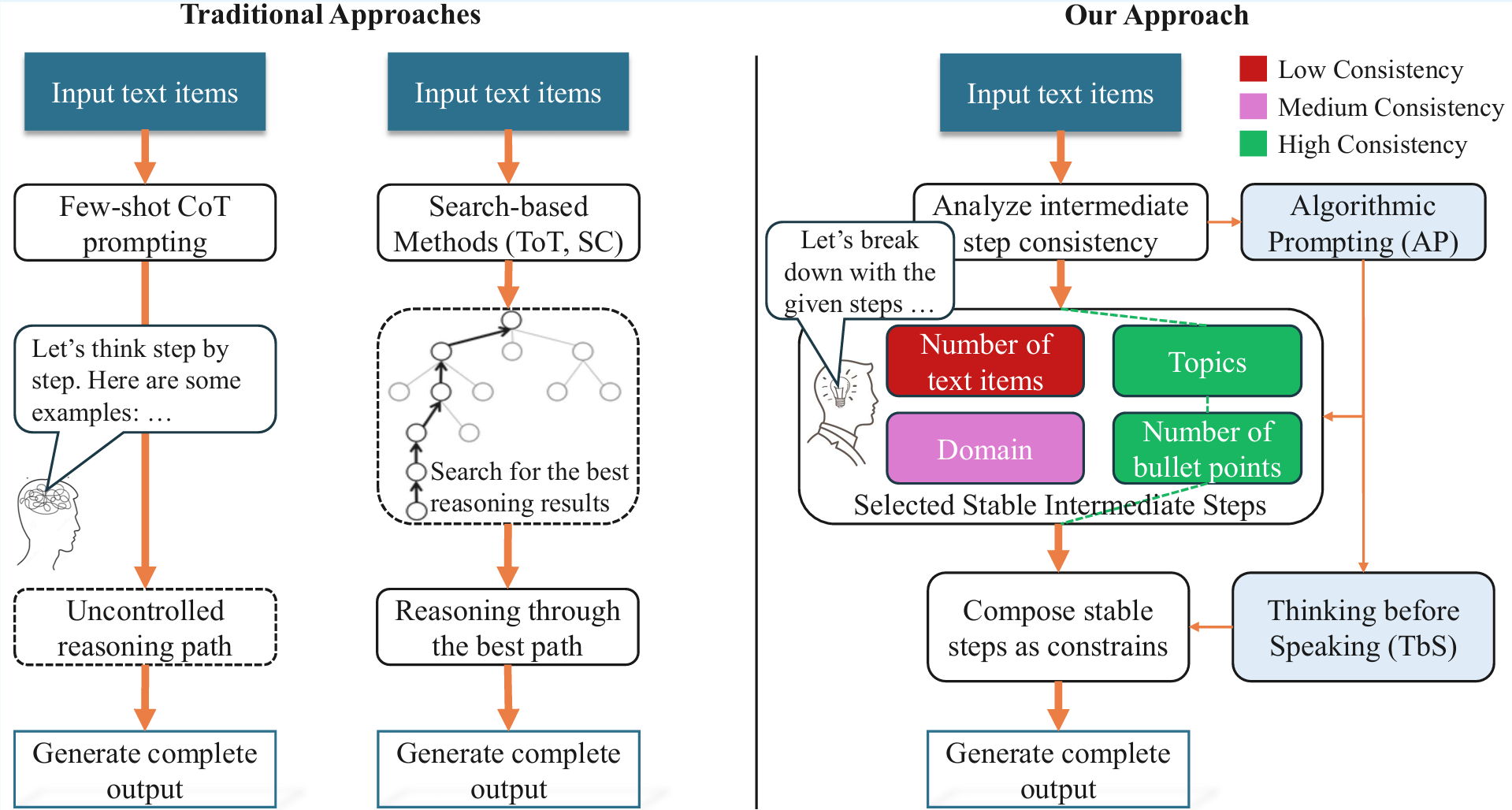
CAST: Achieving Stable LLM-based Text Analysis for Data Analytics
Under Review
AAAI 2025
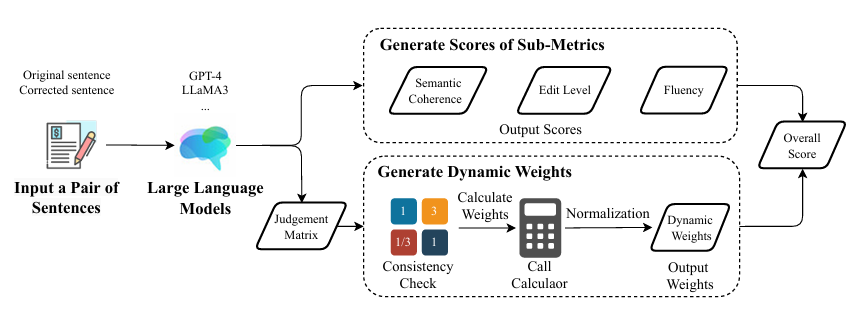
- Qiyang Chen, Yuezhi Wang, Jinxiang Xie, Guozheng Li, Chi Harold Liu. $M^3$ Trader: Multimodal Macro–Micro Inference with LLM-Guided Reinforcement Learning for Quantitative Trading. Under Review.
Educations
- 2025.09 - Present: Master of Science at Kuang Yaming Honors School, Nanjing University.
- 2021.09 - 2025.06: Bachelor of Science in Information and Computing Science, Beijing Jiaotong University.
Internships
- 2024.08 - 2025.08: Research Intern, Data, Knowledge and Intelligence (DKI) Group, Microsoft.
- 2023.11 - 2024.08: Research Intern, Wangxuan Institute of Computer Technology, Peking University.
- 2023.05 - 2023.07: Summer Workshop Student, School of Computer, National University of Singapore.
Blogs
November, 2025
June, 2025

January, 2025

November, 2024

LexiMind: An Open-Source LLM-Powered Vocabulary Builder
LexiMind is an AI-powered vocabulary builder that integrates LLM-based translation with smart word retention.
November, 2023

LLMs: Cutting-Edge Technology and Future Applications
My notes from a presentation on LLMs at the Gaoling School of Artificial Intelligence, Renmin University of China.
August, 2023

Prompt Engineering: How to Better Ask LLMs
Introduce a number of methods for optimizing the output of large language models and reducing the probability of irrelevant or incorrect responses.