
大模型:前沿技术与未来应用
今天去中国人民大学高瓴人工智能学院参加了一个有关大模型的报告,报告请来了来自人大高瓴、北大王选所、中科院计算所、哈工大计算机学院和小米AI实验室等顶尖科研机构的人员。报告的节奏非常快,知识密度非常高,以下是我从有限的记录中回忆出的报告内容:

基于大模型的自主智能体
首先是人大高瓴的陈旭教授,带来用Agent做用户行为分析模拟(Simulation based User Behavior Analysis)的内容。该方法用一个Agent代表一个在互联网上冲浪的人,用神经网络模拟用户的点击、浏览、购买和观看等行为,模拟出一个拥有众多用户的互联网环境。这里有一个难点就是Simulator的构建,Simulator的训练需要大量的真实世界产生的数据,但这些数据往往收集成本比较高,而且对不同领域的Simulator需要重新收集新的数据。一个比较好的解决方法是利用大语言模型优秀的推理和泛化能力,可以用大模型来生成数据用于训练Simulator模型,这样可以极大减少采集数据的成本。
在 Agent 的设计上,该Agent是一个自主智能体,包括LLM、Profiling Module、Memory Module和Action Module四个部分。Profiling Module使用真人和由大模型生成的dataset来构建模拟互联网上用户的信息,如ID,性别,年龄,兴趣和特征等。Memory Module中会将从用户行为中收集到的感知记忆(Sensory Memory)转换为短期记忆(Short-term Memory),然后再通过反复地学习和回忆,将短期记忆再转换为长期记忆(Long-term Memory)。在Action Module 中,系统会根据用户信息、记忆和指令来模拟用户在互联网的行动,最终得到一系列模拟数据。

为了解决系统运行中存在的一系列问题,该系统还可以进行人工干预,比如用真人替代掉其中的一些Agent,比如用指令对系统中的Agent进行控制,还可以修改系统中一些Agent的信息来观察整个系统环境的变化。
以前我认知中的Agent是作为个人的私人助理使用,这是我第一次接触到用Agent进行环境模拟的行为,我觉得这个技术可以和数字孪生、元宇宙等以前比较火的技术结合起来,应该可以在行业中产生一些比较有意思的应用。比如广告主可以在这个模拟环境中测试一下广告投放的效果,根据模拟环境里的数据辅助投放决策。
人大高瓴在今年8月发表了《基于大语言模型的自主智能体综述》,调查了基于大模型的自主智能体的构建、应用和评估方法,有兴趣的同学也可以去了解一下。
大语言模型的知识增强
接着来自哈尔滨工业大学的冯教授分享了他在大模型检索增强方面的心得。检索增强是通过检索知识或额外信息增强大语言模型的方法,该方法在一定程度上可以解决大模型的信息时效性差和幻觉问题。
如何判断大模型是否需要相关知识?
大模型能够回答的问题就不需要检索。判断是否需要检索主要有两种方法,一种是检索判断,即在生成过程中找到其中置信度比较低的词语(比如年份、人名等信息)做检索。第二种就是自我判断,让大模型自我判断是否能回答问题,但这种方法正确率很低,大模型认为自己能够正确回答的问题往往错误率很高,大模型认为自己不能回答的问题反而有较好的表现。所以实际应用中的操作往往是:对于大模型认为能够正确回答的的问题,我们认为大模型对此问题有一些把握,这时我们给他提供一些检索信息,这样反而可以得到比较好的结果。
如何给大模型知识?
在以前的白盒模型中,如果我们想要给模型提供新的知识,只要拿我们有的知识进行微调就行了。在检索模型(Retriever)适配大模型的问题上,因为大语言模型是黑盒模型,而且参数量很大,难以根据搜索结果微调。常用的检索增强(Retrieval-Augmented)的方法具有成本低、速度快等优点,但无法真正优化大模型本身,未来基于用户反馈并配合大模型高校微调和知识编辑技术可实现大模型的自由更新。
检索-生成协作(Retrieval-Generation Cooperation)是指一种基于检索和生成模型的自然语言处理方法,它将检索模型和生成模型结合起来,以实现更加准确和自然的文本生成。在这种方法中,检索模型用于从大量的文本数据中检索相关信息,生成模型则用于将检索到的信息转化为自然语言文本。检索模型和生成模型之间可以通过注意力机制等方法进行交互,以实现更加准确和自然的文本生成。
如何解决信息冲突?
我们可以使用生成式检索来挖掘大模型自身的知识,再用自洽性(self-consistency)等一些Prompt Enginnering的技术,让大模型生成多个结果进行对比。GPT4在内部知识与外部知识冲突的情况下,倾向于优先相信内部知识。改变外部知识与内部知识的比例可以影响模型的选择。

还有一个我很喜欢的观点是:大模型是继数据库和搜索引擎后的全新一代检索和调用方式。在数据库时代,我们需要通过SQL这种结构化的语言来检索和调用数据库中的信息,这个时代涌现出了甲骨文(Oracle)等一批优秀的数据库中。有了搜索引擎后,我们可以使用自然语言来检索想要的信息,降低了检索成本,代表公司有Google。在大模型时代,我们使用自然语言与大模型交互,大模型就可以自动地检索调用和处理好我们想要的信息,有进一步提高了效率,又诞生了OpenAI这样的新巨头。这种说法是有一定道理了,但我认为这三者之间不是完全的迭代关系,他们各有各的优势和应用场景,如果说搜索引擎取代数据库,这种说法是不对的。但展望未来,得益于其优秀的信息处理和检索能力,大模型或许有潜力取代搜索引擎和数据库。
小米的大模型思考和实践
接下来是来自小米技术委员会AI实验室的大模型算法负责人刘伟老师的分享。他先介绍了有关大模型和语言模型的一些基本概念,如语言模型常见地分为自编码语言模型(如BERT)和自回归语言模型(如GPT),使用的是不同的学习方式。自回归语言模型是根据上文或下文预测下一个单词的概率,而自编码语言模型则是将输入token打乱,学习出一个中间表示,再用这个中间表示还原出原始的序列。自编码模型在预测过程中往往会引入一定的噪声以获得更强的创造性,因此现在的大语言模型广泛使用的都是自回归模型。

他介绍小米大模型研究的重点是轻量化和本地部署,因为小米生态拥有众多的终端设备,大多数都没有强大的算力和网络条件来支持目前这些大型的LLM的部署,想要把大模型运用在手机和众多智能家居设备上,轻量化和本地部署是不可避免的。我自己本身也做过大模型这方面的研究,轻量化的常用方法有剪枝、量化和蒸馏等。剪枝分为结构化剪枝和非结构化剪枝,简单来说就是把模型中一些不重要的参数去掉或置为0,以提高模型的推理速度。量化就是把模型中超参数由32bit的浮点类型转换为8、4或者是2bit的整型,这样可以减小模型的体积,从而提高推理速度。蒸馏的方式就比较复杂,花费的成本也更高,指的是把大模型学到的参数提取出来传到小模型当中去,以得到轻量化的大语言模型。
有趣的是,小米还在Tokenizer上花了一些功夫,他们使用BPE作为分词算法,做了一些压缩率的优化,提升了中文的压缩率,提高了转换的效率。可以看出小米在推动大模型的实际应用上下了很多功夫,现有的大模型动辄百亿千亿的参数,虽然能力很强,但像我们平时能接触到的终端设备大多没办法支撑其使用,都必须得依靠云端服务器的强大算力,这是非常不利于大模型在我们日常生活中的实际应用的,希望在不远的将来可以看到大模型能够跑在所有小米的设备上,大大提高我们的生活质量,真正做到让科技改变每个人的生活。
如何用70万训练千亿大模型
来自智源人工智能研究院的王业全老师介绍了他们使用生长技术低成本训练大模型的实践。生长技术就是在训练过程中逐步增加模型的参数,这样可以节约训练资源,用更少的算力资源训练更高参数的大模型。我还是第一次听说这样的技术,在目前中美竞争的背景下,这种训练方式还是很有用的。
接着他介绍了智源训练出的FLM-101B模型的核心架构和创新点。在框架优化方面他们使用了bfloat16(动态范围比float16更大,可以用于替代32位浮点数)、Lion、Flash Attention(在执行自注意力计算时使用分块的方法,在块上执行注意力的计算,提高计算效率)、Megatron的优化方法。接着重点介绍了Mu-Scaling损失预测和FreeLM,但讲的太快了我没听懂……

我关注智源AI的公众号已经有一段时间了,我感觉他们真的是一群很务实的人,在认真思考如何推动大模型的落地和发展。无论是举办智源大会、开源评测模型还是研发FLM,他们一直在努力推动国内大模型生态的发展和繁荣。
从理论视角看自监督学习
这是我印象比较深的一个分享,一是因为老师的胡子和头发很有特色,二是因我之前也是做自监督学习的,三是因为老师的观点确实很厉害,用一套理论把自监督学习给统一起来了。
与有监督学习不同,自监督学习的训练过程与下游任务没有必然的相关性,还省去了大量的标注工作。对比学习(Contrastive Learning)和掩码学习(Masking Learning)是其中的两个代表。在我上大一那会,对比学习是计算机视觉领域炙手可热的技术,甚至有人称其为CV领域的Transformer。它将训练集中的一张图片增强后作为正样本,将数据库中的其他图片作为负样本进行训练,尽量拉开正负样本之间的距离,这样就可以把同类的样本聚集在一起,实现图像分类的任务。对比学习使用一种名为NCE Loss的损失函数,可以很好地实现这个需求,NCE Loss可以拆分成两个部分,分别实现Alignment和Uniformity的功能。

接下来是他们的工作,他提出了用augmentation graph connectivity来解释对比学习的效果。在对比学习中augmentation graph是通过对输入图进行数据增强后构建的图,在输入空间中相关性高的样本在增强后就会重叠到一起,出现augmentation overlap的现象,他们发现相同样本在增强后overlap越多,即augmentation graph connectivity越强,对比学习的效果就越好。同样地,在掩码学习中,如果把掩码后的图像看作正样本,也可以绘制出相应的augmentation graph,用来解释掩码学习效果。

这种图还可以解释为什么CLIP在众多视觉预训练模型中脱颖而出,用SimCLR学习时可能会把不同特征的狗分类到不同的cluster中,但在CLIP中由于有文字的辅助训练,让这些不同特征的狗可以被分到一个cluster中,也就是在augmentation graph中把这些狗连通起来了,得到了一个连接图(虽然并不是全连接图),所以CLIP相比SimCLR等方法有更好的效果。
扩散模型与视觉内容生成
下午的报告同样也很精彩,首先是李崇轩老师介绍了他们在扩散模型和视觉内容生成方面取得的进展。扩散模型是Midjourney和Stable Diffusion等AI绘图工具背后的重要技术,也是在ChatGPT之前最重要的突破之一,该方法让文生图模型拥有了前所未有的理解能力和泛化能力,相比原先的GAN网络,采用扩散模型可以创造出很多有创造性的图片。李老师还介绍了他们在三维内容生成和用AI调整图片的Demo,轻轻拖动鼠标就可以改变图中动物的神态和动作很让人印象深刻,因为不是我熟悉的领域,我就不做过多的叙述了。
多模态大模型
我相信大多数人都相信多模态大模型是未来一个很重要的方向,大模型将会可以处理并输出越来越多的模态,可能最终会把视觉、听觉和语言模型都统一成一个大模型。来自北大王选计算机研究所的穆老师介绍了构建多模态模型的几种方法。
首先是他们与字节合作开发的用于电商的大模型——ECLIP,该方法和OpenAI的CLIP类似,可以同时对图片和文字信息进行编码,然后进行图片文字的对比学习,该模型可以用于筛选详情页和评论中的有关商品。
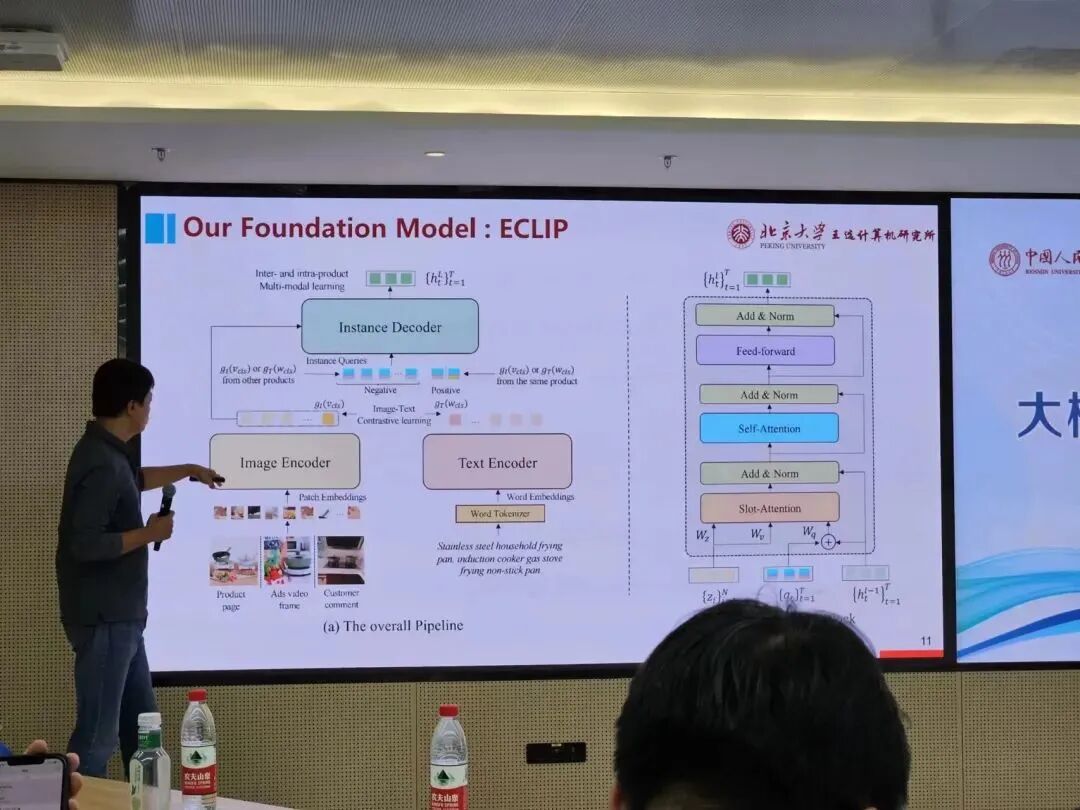
另一种实现多模态的方法是用大语言模型来做处理,前面接一个Text Tokenizer和一个Visual Tokenizer,将多模态的输入都转换成大语言模型可以理解的形式,用自回归的方式来得到一个多模态的预训练模型。

大模型在金融行业的落地和应用
接下来是来自中科院计算所的敖翔老师分享了他对大模型在金融行业落地的前景和思考。他首先简单回顾了大模型的发展历程和安全风险,PPT上列出的详细总结引的大家纷纷举起手机拍照。谈到在金融行业的落地场景,他指出目前能够落地的智能客服、文档审核、信息抽取和文案生成工作并不是金融行业独有的,在其他行业也依然适用。而金融行业期望的数据信息的定量分析与解释,如收入预测、量化交易和信用评级等核心诉求,大模型目前并没有办法做到,大模型要真正在金融行业落地还有很长的路要走。
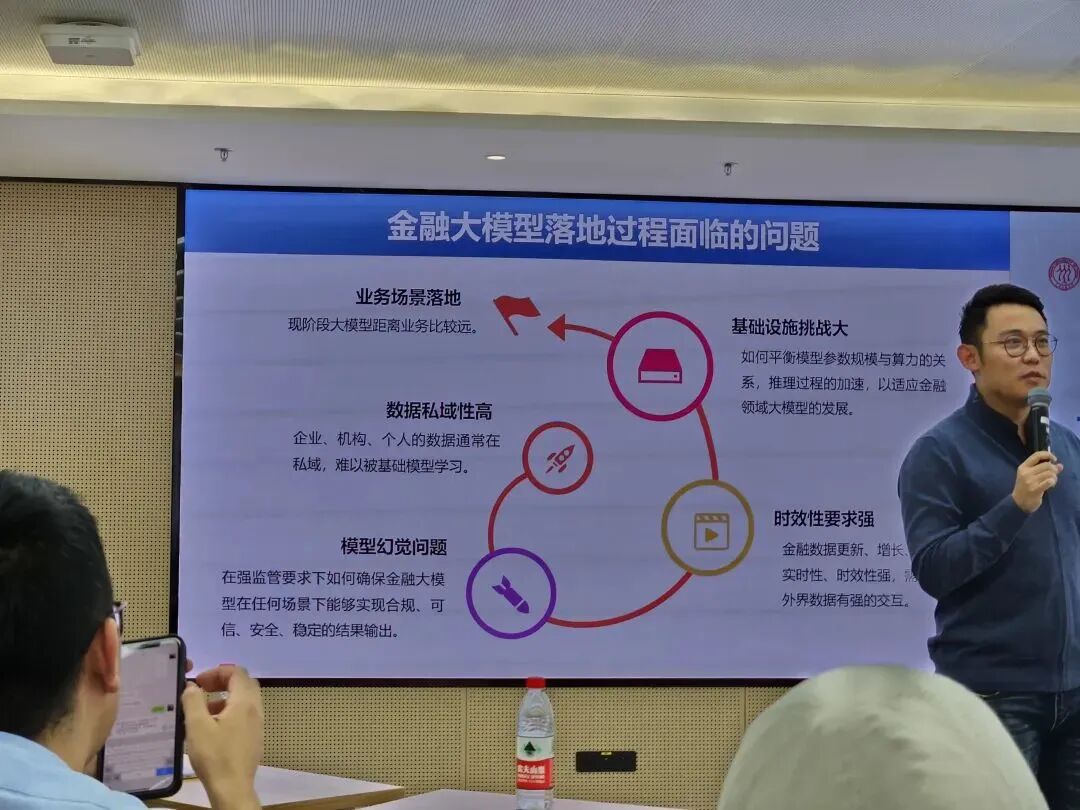
大模型已经被证明在文本、图像数据的任务上有很好的表现,但在处理多源异构的用户数据上还存在着空白,这是传统的自然语言处理和计算机视觉的方法所解决不了的,所以未来可能需要越来越多数据科学背景的人加入到大模型研究中来,将大模型强大的理解和推理能力运用到分析用户数据当中,大模型才有可能实现在风控行业的应用。
敖老师讲了两个未来大模型在金融领域可能的研究方向。
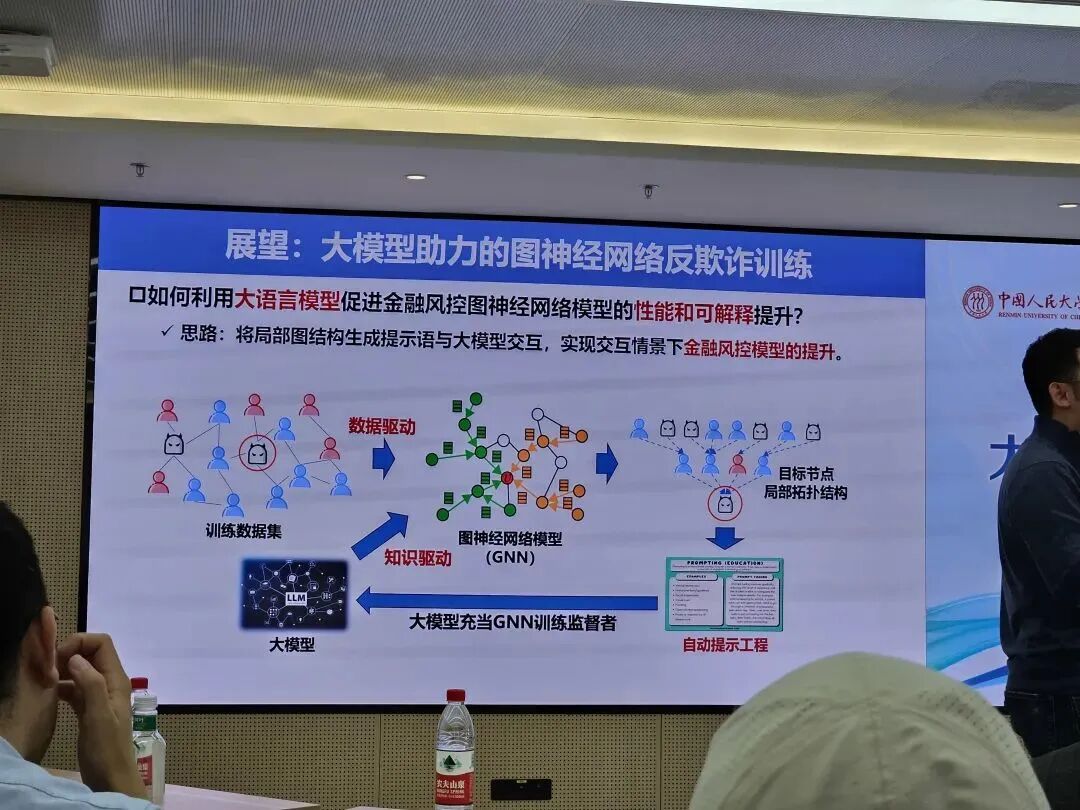
一是大模型助力的图神经网络反欺诈训练。图神经网络(GNN)是用于处理图结构的深度神经网络,可以很好地捕捉图结点间的关系和拓扑结构。近年来图神经网络被广泛应用于金融领域反欺诈,但传统图神经网络仍属于数据驱动的范式,面临着数据不可信为,模型缺少可解释性的挑战。对此可以引入大模型作为监督者来监督GNN的训练,将局部图结构生成提示语与大模型交互,实现交互场景下金融风控模型的提升。
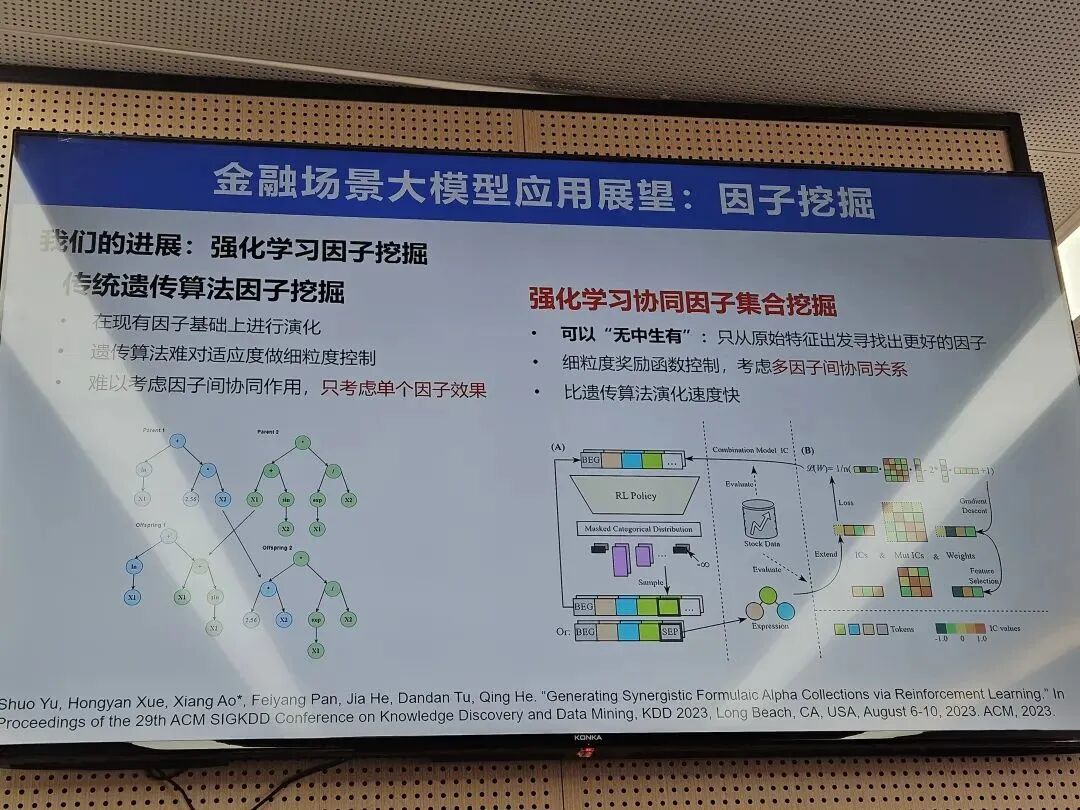
第二个可能的方向是量化选股的因子挖掘。因子挖掘(Factor mining)是量化交易中的一个重要概念,指从市场数据中挖掘有价值的影响因素,用来指导量化团队的工作。传统的遗传算法可以进行因子挖掘,但只是在现有的因子基础上进行演化,难以对适应度做细粒度的控制,难以考虑因子间的协同作用只考虑单个因子效果。使用强化学习协同因子集合挖掘就可以解决这些问题,用表达树的后序遍历顺序将数结构线性化成一串token,再用LSTM等自回归序列生成模型生成因子表达式,然后就可以使用强化学习算法来优化模型。有了大模型之后,大模型或许也可以帮助因子挖掘,用于根据投资者的描述生成因子和用自然语言总结挖掘结果,构建一套用于因子挖掘的人机协同系统。
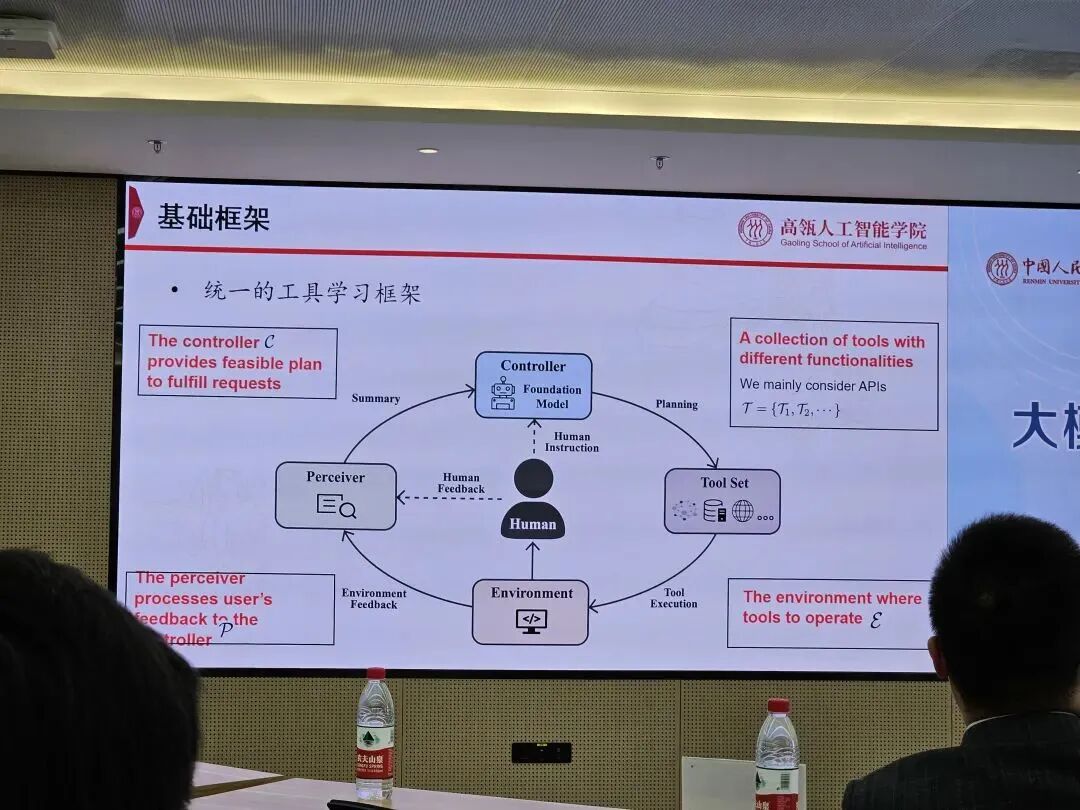
大模型工具学习
接着是有关大模型工具学习的分享,即让大模型学会使用工具,增强模型自主解决复杂任务的能力。林老师团队试图构建一个统一的基础框架,给大模型提供一个良好的Perceiver、Controller、Tool Set和Environment,让大模型可以根据用户的不同需求,使用不同的工具解决任务。比如让大模型学会使用搜索引擎,他们通过模拟人类使用搜索引擎的点击和滚动等行为对大模型进行有监督微调加强化学习,只需6000个注释数据就可以达到接近人类的搜索引擎使用水平。其他诸如ToolBench、Elo树搜索和XAgent我就不过多介绍了。XAgent的愿景很不错,希望可以建立统一的智能体语言,通过海量的外部工具和Docker执行环境让智能体能够更好地为用户服务。
端侧大模型
接着来自小米的邓巍老师介绍了小米在端侧视觉大模型方面的研究。他介绍了视觉模型从特定任务模型到预训练模型再到如今多模态大模型的发展历程,还介绍了文生图大模型的基本框架,接着以小米相册搜索为例介绍了他们的大模型实践,我也不过多赘述了。
