

Claude Code Skills 和 Subagents 的个人实践
网上关于 Claude Code 的文章不少,但多数还停留在「怎么接 MCP」「怎么接第三方大模型」这种入门层面,对 Skills 和 Subagents 的讨论往往浅尝辄止,很少有人真的用它们撑起一个
生产级科研工作流。
过去几个月,我系统地研究了 Anthropic 的 Claude Code 文档,并用它搭建了两个面向真实科研场景的系统:
- 一个可以大规模、跨付费墙下载论文的自动化文献下载 Agent
- 一个在特定数据集上自动迭代优化预测算法的「自迭代 AI Scientist」
这篇文章会把这两套系统拆开讲,重点放在三件事:
- Skills 和 Subagents 到底在实践中扮演什么角色
- 它们如何把 LLM 从「聊天工具」升级成生产级科研基础设施
- 在长时间运行、复杂优化任务中,你会遇到哪些真实的坑
接下来分为两部分讲述。
一、AI驱动的自动化文献下载 Agent
在生命科学和化学研究中,我长期陷入同一种疲惫。在进行文献数据收集时,由于大量文献并不是 Open Access 的,每天打开学校 VPN,手动搜索几十篇文献,点击下载,命名,再塞进本地文件夹。效率惨不忍睹。传统爬虫难以覆盖复杂业务逻辑,加上跨站点授权处理困难,于是我开始尝试让 Claude Code 接管整条流程。
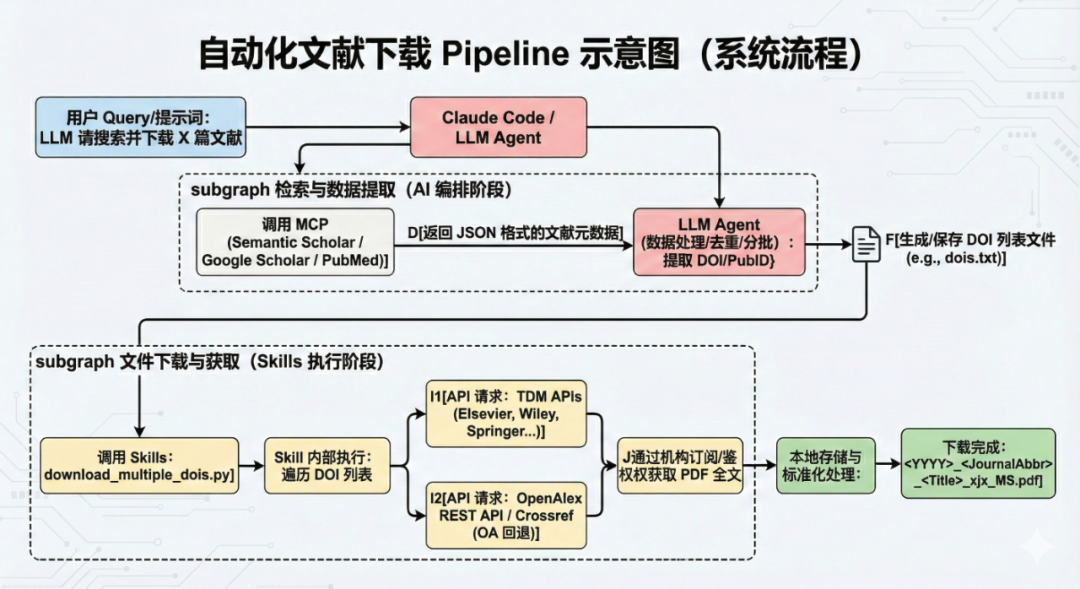
下面是最终的系统结构图。
 AI驱动的自动化文献下载Agent示意图(由Nano Banana Pro生成)
AI驱动的自动化文献下载Agent示意图(由Nano Banana Pro生成)
第一阶段:从 Agent 到 Skill 的演变
最初的尝试集中于构建一个具备严格执行力的独立智能体,用于处理多肽自组装主题的文献收集。
最初我构建了一个专门服务于多肽自组装主题的 Agent,其核心任务是进行全面的文献综述,系统性地搜索、下载、组织并遵循严格的命名和去重协议。
- 搜索与去重: Agent 利用 MCP 访问外部系统和学术数据库(如 Semantic Scholar, PubMed, Biorxiv, Sci-Hub)进行文献查找。在添加任何新文献之前,它被要求必须检查本地的
total.htm文件以确保不重复。 - 标准化命名: 严格遵循统一的命名格式,例如:
<YYYY>_<JournalAbbr>_<Sanitized-Title>_MS.pdf。 - 成果: 首次运行该 Agent 大约花费了 10 分钟,进行了 32 次工具调用,并成功交付了 50 篇新的多肽自组装文献。
经过测试我发现,通过 MCP 能检索到的文献很多,但只能下载其中一部分 Open Access 的文献,而且下载很不稳定,这大大限制了下载到本地的文献数量。这促使我寻找能够跨越付费墙、或者通过机构订阅进行下载的方式。
虽然 Agent 在小规模任务中表现优异,但要应对大规模数据下载,需要更专业的工具集成,尤其是针对付费文献。
我发现可以利用机构订阅的权限,通过 Springer, Elsevier 和 Wiley 的 TDM (Text and Data Mining) API 获取付费墙内的文献全文本。对于开放获取(OA)文献,则使用 OpenAlex REST API 进行检索和下载。
为了将这些专业的 API 调用逻辑和批量处理能力集成到 Claude Code 的自动化工作流中,我采用了 Skills 机制。
Skills 是项目内的功能脚本集合,用于封装具体的工作流步骤。通过将「按 DOI 下载论文PDF」的能力封装成 Skill,Agent 可以在研究流程中直接、高效地调用。
核心脚本: 我创建了 .claude/skills/paper-download Skill,包含了用于单个 DOI 下载的 download_by_doi.py 和支持批量下载的 download_multiple_dois.py 脚本,以及关于该 Skill的说明 SKILL.md。
(如果您想要有更直观的感觉,可以到我的GitHub库里查看SKILL文档的全文)
至此,Agent 不再负责实现逻辑,只做调度。需要检索文献的时候调用MCP,需要下载文献的时候调用Skills,有了这些坚实的基础设施,我想要下载文献的时候只需要给一句简单的 prompt 「帮我下载100篇xxx领域的文献」即可。
第二阶段:大规模测试与鲁棒性优化
有了 Skills,下载能力稳了下来。我用 15293 条多肽自组装相关文献信息做了压力测试,结果如下:
- 总成功率:最终成功下载了 9071 篇 PDF,总成功率达到 59.3%。
- 渠道表现:得益于 TDM API 的使用,受机构订阅支持的渠道下载成功率极高:Elsevier 成功率 99.8%,Wiley 成功率 95.9%。这证明了结合机构 API 是解决付费文献大规模获取问题的有效途径。此外,工作流中还引入了 Unpaywall 回退机制来补充缺失的 OA 链接。
这说明「AI 检索 + TDM API 下载」的组合非常有效。
但新的问题出现了。
在测试过程中,一个显著的困难浮现出来:Agent 在处理巨量下载任务(例如要求下载 10000 篇文献)时,会出现偷懒行为,在完成约 200 篇后就提前结束对话。这与学界观察到的
上下文坍缩(Context Collapse)现象有一定关联,即 Agent 在上下文过长时倾向于过度压缩信息,导致准确率下降或行为异常。
为了解决这个问题,我先在工作流中增加了严格的约束和分批次处理逻辑:
- 限制搜索结果数量: 明确规定在使用 MCP 搜索文献时,必须限制返回结果数量(例如
max_results不超过 50),以避免上下文窗口过载。 - 分批次执行: 面对大型下载任务,Agent 必须将任务拆分成更小的部分,例如将 DOI 列表保存为
doi_batch_1.txt,doi_batch_2.txt,doi_batch_3.txt,然后按顺序执行下载 Skill。 - 在后台执行命令: 可以利用 Claude Code 提供的后台命令功能来规避命令执行超时的问题,只需要简单地在
CLAUDE.md里加上”Always execute download command in the background”的记忆即可。
通过这种方式,Agent 的鲁棒性得到了提升,能够更有效地管理其上下文,从而完成大规模的自动化任务,但还是时常会出现提前结束任务的问题。
一个更优雅的解决方法是使用一个叫做 continuous-claude 的开源库,这个库使用Git的方式来管理任务进度,Claude 可以持续运行直到完成用户设定的结果。
小结:AI 驱动科研工作流的价值
Claude Code 提供的 MCP 和 Skills 框架,使得我们将复杂的科研逻辑(多来源检索、API 鉴权、去重、标准化命名)从 LLM 的推理层剥离出来,封装在稳定、可控的脚本中。LLM 则专注于其擅长的
任务编排、检索式生成和结果过滤。这种结合了 LLM 编排能力和专业代码执行的自动化文献管道,将原本需要数周的手动工作(文献收集和初步组织)压缩到了极短的时间,为后续的信息提取和更深层次的科研工作打下了坚实的数据基础。
自动化文献下载项目已经开源在GitHub,欢迎Star!(https://github.com/jxtse/auto-paper-harvester)
二、自迭代 AI Scientist
自动化文献下载项目解决的是「数据入口」问题。真正让人上头的部分,其实是:能不能在此基础上,让 AI 自己去调模型、跑实验、迭代配置。
于是,在另一个项目里,我用 Claude Code 搭建了一个「自迭代 AI Scientist」。它负责自主优化一个结构化预测任务,通过不断进行「生成想法 -> 实现代码 -> 跑实验 -> 总结结果 -> 再生成新想法」的闭环迭代,在有限轮次内尽量把验证集上的 c-index 拉高。
早期版本的实验管线是这样的:
- Python 脚本驱动 LLM 做特征选择和算法设计
- 再用 Codex 或 Claude Code 实现算法代码
- 代码跑完以后,输出验证集上的 c-index 结果(c-index 是一种用于衡量「排序一致性」的评估指标,这里可以粗略地把它理解成「验证集表现分数」,和 R²、MSE 一样用来衡量模型好坏。)
- 脚本把这个 c-index 反馈给 LLM,让它在下一轮调整特征和模型结构
- 重复,形成一个闭环优化过程
在这个阶段已经能让 LLM 生成非常复杂的算法 blueprint,包括特征工程、正则化、损失函数、评估方案、文献引用等等。但有两个现实问题迅速出现:
- 实现层面很不稳定:Claude Code 和 Codex 都有「写到一半停手」的倾向,经常需要多轮提示才能得到完整可靠的代码。
- 迭代效果很快触顶甚至开始下滑:第一轮迭代会有一点提升,再继续迭代,c-index 反而下降。
这提醒了一件事:LLM 在缺少结构化上下文时非常容易失焦。没有清晰的科学工作流和状态管理,让它「自己瞎改」,很快就会从局部贪心变成随机游走。
用 Skills 和 Subagents 加速迭代:让 Claude 连续跑上几个小时
我最终把整套系统拆成两个部分:
- 1个 Skill:专门负责「迭代想法」
- 4个 Subagent:专门负责「实现代码并跑完」
Claude 负责 orchestrate 整个循环,好处很明显:
- 每个 Subagent 的 role 非常清晰,不容易 stuck
- Claude Code 只协调,不需要记住所有历史
- 结构化文件成为上下文来源
- 整个系统可以连续运行几个小时
系统整体架构
整体prompt设定为:
你正在协调一个多 Agent 系统,目标是在多轮迭代中优化一个预测模型,主要衡量标准为验证集上的c-index值表现。
它调用四个职责分明的 Subagent:
Subagent 1:Algorithm-Implementer
这个 Subagent 负责「落地与执行」。根据本轮的特征集合、上游生成的建模思路和给定的超参数配置文件,根据想法和规格实现模型,输出训练日志和验证集性能,并保存模型 checkpoint、运行中间产物和总结文档。
输出文件结构如下(按轮次保存):
results.json:包含本轮指标表现model_checkpoint.pt:模型权重training_log.txt:训练日志implementation_summary.md:实现与思路总结
Subagent 2:Feature-Selection-Agent
这个 Subagent 负责「特征归纳、选择与生成」。它需要根据数据集中当前的全部特征、本轮训练后的实现总结,以及历史中所有尝试过的特征与想法调整当前的特征集。
它会:
- 基于历史表现推断哪些特征有贡献
- 快速进行 web search 以了解各个特征的含义
- 排查冗余或高度相关特征
- 适度提出组合特征或轻量化派生特征
- 给出明确的特征选择理由(可解释化)
输出:
selected_features.json(特征集与理由)
Subagent 3:Idea-Iteration-Agent
这是「模型创新组」,负责提出新尝试。它根据 Subagent 2 提供的新特征集合、先前 Subagent 1 提供的实现总结,以及历史想法档案迭代出新的想法。
它会:
- 生成新的建模思路
- 根据失败案例提出修复或规避方案
- 对本轮特征提出匹配度较高的设计 输出:
ideas.json:多条按优先级排序的想法清单
Subagent 4:Optimization-Algorithm-Agent
负责将想法具体化为训练配置。根据 Subagent 3 生成的想法,选择合适的 batch size、epoch 数、early stopping 规则,配置正则化强度、限制条件等
输出:
config.yaml:完整可执行的训练配置
所有的 Subagent 被完善地定义在 .claude/subagents 文件夹当中,可以在 Claude Code 中输入 /agents 命令进行快速查看和编辑。其中负责特征选择的 Subagent 2 被提供了快速查看数据集中的 column name 以及少量样本的 skill;负责迭代想法的 Subagent 3 被提供了调用LLM API迭代想法的 skill,这个 skill 包含了精心设计的迭代 prompt。
通过预定义的 Subagents 和 Skills,LLM 可以自主地主持迭代过程和协调任务,更加省时、有效地完成优化任务。
三、两个项目抽象出的 Claude Code 最佳实践:从「对话」到「基础设施」
回顾这两个项目,无论是处理 15,000 条文献的下载,还是让 AI 科学家连续数小时自我迭代,我发现所有的技术难点最终都指向了同一个核心矛盾:
LLM 的概率性生成与复杂任务对确定性、持久性要求之间的冲突。
在任务规模扩大和上下文负载增加时,LLM 几乎必然会出现「倒退行为」——表现为变懒、遗忘指令、或者在循环中迷失。这种物理规律难以单纯依靠 Prompt Engineering 来规避。
通过这两个项目的反复踩坑与重构,我总结出了一套在 Claude Code 中构建生产级 Agent 的核心模式,我将其概括为:
重 Skill,轻 LLM 与结构化状态流转。
1. 把负载从推理层转移到执行层
这是最重要的一条原则:不要让 LLM 充当 CPU,让它做 CPU 的调度器。
在文献下载 Agent 的早期,我曾尝试让 LLM 记住下载列表,通过 Prompt 让它「通过循环一个个下载」。结果是它在处理几十个文件后就开始出现幻觉或自行终止。解决之道的关键在于降维:
- 凡是涉及循环、计数、精准匹配的逻辑,一律下沉为 Python 代码(Skills)。
- LLM 的职责仅限于:理解意图 -> 组装参数 -> 调用 Skills -> 检查返回值。
在 AI Scientist 中也是同理,计算 c-index、切分数据集这些工作完全封装在 Skill 内部。Skills 就像是为 LLM 装上的义肢,越是重型的计算和逻辑,越应该做成 Skill。这样,LLM 的上下文窗口不再被冗长的过程数据填充,只保留最关键的决策信息。
2. 将 Subagent 作为上下文防火墙
在单体 Agent 模式下,随着对话轮次增加,Prompt 中会堆积大量的异构信息(代码片段、报错日志、无关的闲聊),导致上下文信噪比急剧下降,这是 AI Scientist 早期迭代效果触顶下滑的根本原因。
引入 Subagents 的本质,不仅仅是角色扮演,更是为了建立上下文防火墙:
- Feature-Selection Agent 不需要知道 Algorithm-Implementer 具体的 PyTorch 代码写得有多烂,它只需要看
results.json。 - Idea-Iteration Agent 不需要关注具体的 API 鉴权细节,它只需要专注于 ideas.json 的逻辑推演。
每个 Subagent 都在一个干净、独立的上下文中运行,完成任务后即销毁,只向下游传递经过压缩的高价值信息(Summary/JSON)。这种架构极大地延缓了上下文污染的速度,使得系统能够进行长程的自我迭代。
3. 状态外置,而非内置
在传统的 Chat 模式中,我们习惯认为对话历史 = 记忆。但在生产级工作流中,对话历史是最不可靠的存储介质。在我的两个系统中,真正的状态从未保存在 LLM 的脑子里,而是保存在文件系统中:
- 文献下载进度保存在
total.htm和doi_batch.txt。 - AI 科学家的进化路径保存在
ideas.json和config.yaml。 - 任务的执行流转依靠 continuous-claude 的 Git 提交记录。
这种「文件即状态」(File-as-State)的设计,使得 LLM 可以随时掉线、重启、甚至更换模型,而工作流不会中断。Claude Code 在这里扮演的角色,不再是一个时刻需要保持清醒的全知全能者,而是一个看着操作手册(Context)、操作控制台(Skills)、读写档案(Files)的操作员。
四、结语
从早期的Chatbot到如今的 Claude Code,我们正在经历一种范式的转变:
从 Prompt Engineering 走向 Context Engineering。
自动化文献下载 Agent 证明了:通过 MCP 和 Skills,我们可以用自然语言驱动复杂的传统软件业务逻辑。
自迭代 AI Scientist 证明了:通过 Subagents 和结构化状态管理,我们可以让 LLM 突破一次性对话的限制,展现出类似人类科学家的长时程推理与探索能力。
Claude Code 给了我们一个极其顺手的脚手架。它让我们意识到,构建强大的 AI 应用,关键往往不在于写出多么惊艳的 Prompt,而在于通过 Skills 和 Subagents,为模型构建一个
确定性的、可观测的、容错的生存环境。
未来,这种LLM 编排 + 专业代码执行 + 多智能体协作的模式,或许将成为科研自动化的新常态。